
Nginx根据user_agent控制屏蔽访问
•
Nginx配置
对于做国内站的我来说,我不希望国外蜘蛛来访问我的网站,特别是个别垃圾蜘蛛,它们访问特别频繁。这些垃圾流量多了之后,严重浪费服务器的带宽和资源。通过判断user agent,在nginx中禁用这些蜘蛛可以节省一些流量,也可以防止一些恶意的访问。
1、进入nginx的配置目录,例如cd /etc/nginx/conf;
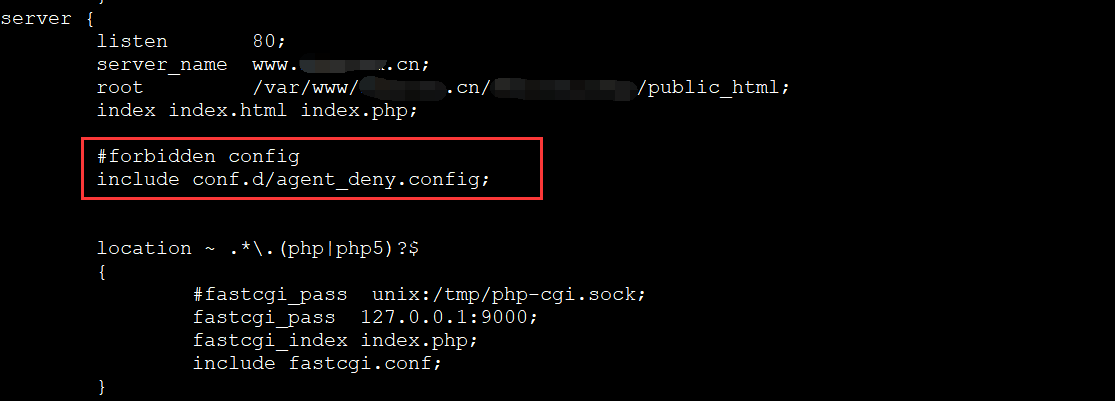
2、添加agent_deny.conf配置文件 vim agent_deny.config;
3、在对应站点配置文件中包含deny_agent.config配置文件(注意是在server或者location里面);
4、平滑重启nginx,使配置生效;
5、使用curl -A 模拟抓取模拟访问测试。
[root@iz conf]# curl -I -A 'YYSpider' www.wwww.com HTTP/1.1 403 Forbidden
禁止空agent的浏览器访问
if ($http_user_agent ~ ^$) {
return 403;
}
禁止Scrapy等工具的抓取
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
禁止指定UA的访问
if ($http_user_agent ~ "ApacheBench|WebBench|HttpClient|Java|python|Go-http-client|FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Feedly|UniversalFeedParser|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|MJ12bot|heritrix|EasouSpider|LinkpadBot|Ezooms" )
{
return 403;
}
| UA类型 | 描述 |
| ApacheBench | cc攻击器、性能压测 |
| WebBench | cc攻击器、性能压测 |
| WinHttp | 采集cc攻击 |
| HttpClient | tcp攻击 |
| Jmeter | 压力测试 |
| BOT/0.1 (BOT for JCE) | sql注入 |
| CrawlDaddy | sql注入 |
| Indy Library | 扫描 |
| ZmEu phpmyadmin | 扫描 |
| Microsoft URL Control | 扫描 |
| jaunty | wordpress爆破扫描器 |
| Java | 内容采集 |
| Python-urllib | 内容采集 |
| Jullo | 内容采集 |
| FeedDemon | 内容采集 |
| Feedly | 内容采集 |
| UniversalFeedParser | 内容采集 |
| Alexa Toolbar | 内容采集 |
| Swiftbot | 无用爬虫 |
| YandexBot | 无用爬虫 |
| AhrefsBot | 无用爬虫 |
| jikeSpider | 无用爬虫 |
| MJ12bot | 无用爬虫 |
| oBot | 无用爬虫 |
| FlightDeckReports Bot | 无用爬虫 |
| Linguee Bot | 无用爬虫 |
| EasouSpider | 无用爬虫 |
| YYSpider | 无用爬虫 |
PS:一些常见爬虫的User-Agent,这些一般就不要过滤了~
- 百度爬虫
- Baiduspider+(+http://www.baidu.com/search/spider.htm”)
- google爬虫
- Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
- Googlebot/2.1 (+http://www.googlebot.com/bot.html)
- Googlebot/2.1 (+http://www.google.com/bot.html)
- 雅虎爬虫(分别是雅虎中国和美国总部的爬虫)
- Mozilla/5.0 (compatible; Yahoo! Slurp China; http://misc.yahoo.com.cn/help.html”)
- Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp”)
- 新浪爱问爬虫
- iaskspider/2.0(+http://iask.com/help/help_index.html”)
- Mozilla/5.0 (compatible; iaskspider/1.0; MSIE 6.0)
- 搜狗爬虫
- Sogou web spider/3.0(+http://www.sogou.com/docs/help/webmasters.htm#07″)
- Sogou Push Spider/3.0(+http://www.sogou.com/docs/help/webmasters.htm#07″)
- 网易爬虫
- Mozilla/5.0 (compatible; YodaoBot/1.0; http://www.yodao.com/help/webmaster/spider/”; )
- MSN爬虫
- msnbot/1.0 (+http://search.msn.com/msnbot.htm”)
禁止爬虫抓取
if ($http_user_agent ~* "qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo! Slurp|Yahoo! Slurp China|YoudaoBot|Sosospider|Sogou spider|Sogou web spider|MSNBot|ia_archiver|Tomato Bot")
{
return 403;
}
禁止非GET|HEAD|POST方式的抓取
if ($request_method !~ ^(GET|HEAD|POST)$) {
return 403;
}
禁止特殊的user_agent的访问
if ($http_user_agent ~ "Mozilla/4.0\ \(compatible;\ MSIE\ 6.0;\ Windows\ NT\ 5.1;\ SV1;\ .NET\ CLR\ 1.1.4322;\ .NET\ CLR\ 2.0.50727\)") {
return 404;
}
禁止或者转发
- return 404;
- proxy_pass http://www.google.com;