
1、Trie树和Radix树的区别
1.1 Trie树(前缀树、字典树)
Trie树特点
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符;
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;
- 每个节点的所有子节点包含的字符都不相同。
Trie树又叫前缀树,是一个多叉树,广泛应用于字符串搜索,每个树节点存储一个字符,从根节点到任意一个叶子结点串起来就是一个字符串。
Trie树优点:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
1.2 Radix树(基数树、压缩前缀树)
Radix树,即基数树,也称压缩前缀树,是一种提供key-value存储查找的数据结构。与Trie不同的是,它对Trie树进行了空间优化,只有一个子节点的中间节点将被压缩。同样的,Radix树的插入、查询、删除操作的时间复杂度都为O(k)。
Radix树特点
- 一般由根节点、中间节点和叶子节点组成;
- 每个节点可以包含一个或多个字符;
- 树的叶子结点数即是数据条目数;
- 从根节点到某一节点经过路径的字符连起来即为该节点对应的字符串;
- 每个节点的所有子节点字符串都不相同。
1.3 图示区别
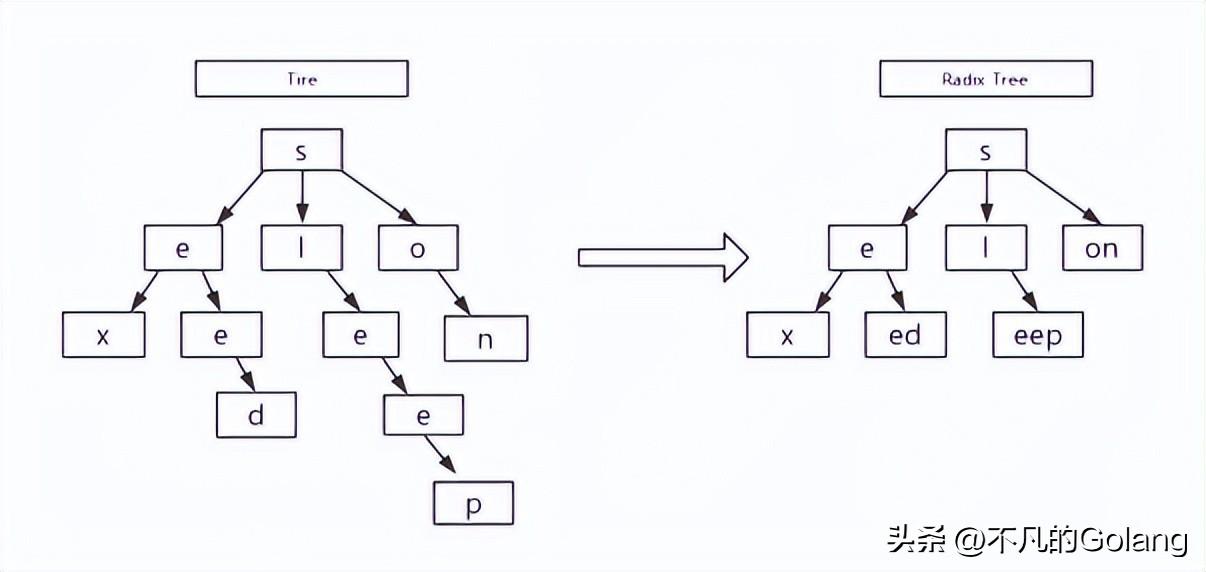
下图左侧是字符串 sex,seed,sleep,son 四个字段串的Trie数据结构表示。可以看到sleep这个字符串需要5个节点表示. 其实e后面只跟一个p, 也就是只有一个子节点, 是完全可以和父节点压缩合并的。右侧是优化后的数据结构, 节省了空间,同时也提高了查询效率(左边字符串sleep查询需要5步, 右边只需要3步), 这就是radix tree。
2、Gin框架路由原理
httprouter是一个高性能路由分发器,它负责将不同方法的多个路径分别注册到各个handle函数,当收到请求时,负责快速查找请求的路径是否有相对应的处理函数,并且进行下一步业务逻辑处理。golang的gin框架采用了httprouter进行路由匹配,httprouter 是通过radix tree来进行高效的路径查找;同时路径还支持两种通配符匹配。
httprouter会对每种http方法(post、get等)都会生成一棵基数树,其中树节点node结构如下:
type nodestruct {
path string //该节点对应的path
indices string //子节点path的第一个byte的集合
wildChild bool //是否通配符
nType nodeType //节点类型
priority uint32
children []*node //子节点
handlers HandlersChain //handle如果不为nil,则说明是一个路径字符串的终点!!!
fullPath string
}
type nodeType uint8
const (
static nodeType =iota // default 普通节点
root //根节点
param //参数节点 /user/{id},id 就是一个参数节点
catchAll //通配符
)
Gin注册路由过程
如下左边是/sex,/sleep,/son的内部呈现, 右边是插入/seed 后内部的呈现:
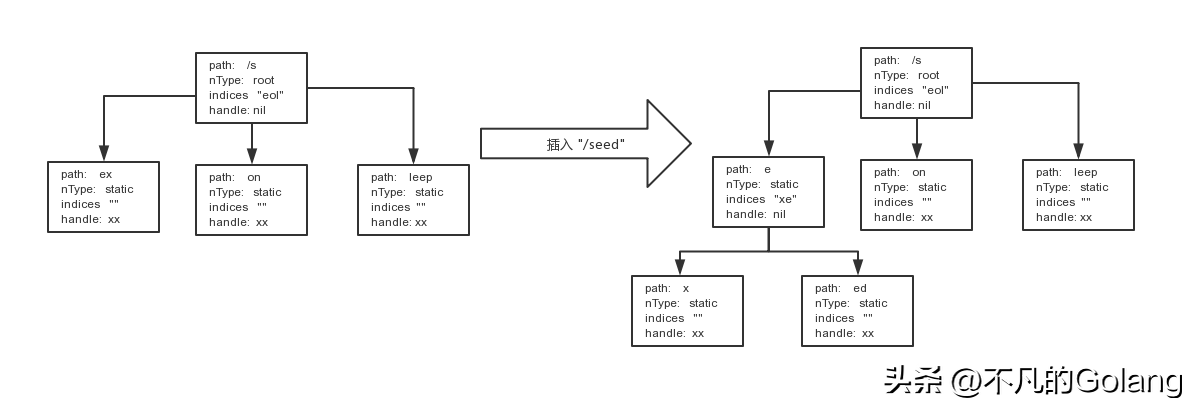
简单地来说每一个注册的 url 都会通过 / 切分为 n 个树节点(httprouter 会有一些区别,会存在根分裂),然后挂到相应 method 树上去,所以业务中有几种不同的 method 接口,就会产生对应的前缀树。在 httprouter 中,节点被分为 4 种类型:
— static – 静态节点,/user /api 这种
— root – 根结点
— param – 参数节点 /user/{id},id 就是一个参数节点
— catchAll – 通配符
其实整个匹配的过程也比较简单,通过对应的 method 拿到前缀树,然后开始进行一个广度优先的匹配。
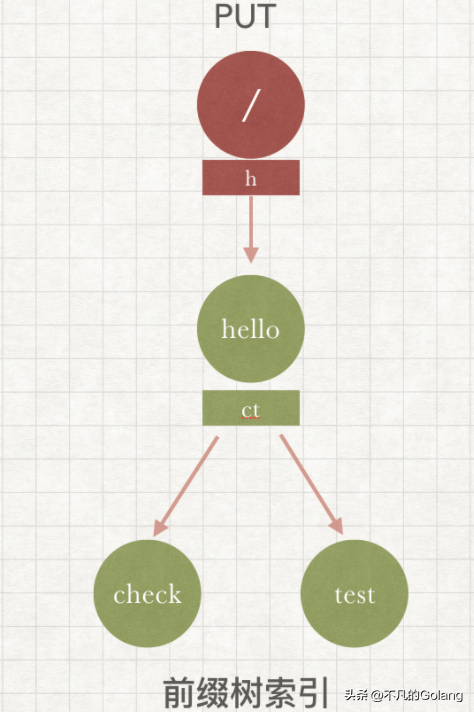
这里值得学习的一点是,httprouter 对下级节点的查找进行了优化,简单来说就是把当前节点的下级节点的首字母维护在本身,匹配时先进行索引的查找。
注意
gin中相同http方法的路由树中,参数结点和静态结点是冲突的,也就是:
get 方法,如果存在了 /user/:name这样的路径,就不能再添加/user/getName这样的静态路径,否则会报冲突。