
负载均衡配置一般都需要同时配置反向代理,通过反向代理跳转到负载均衡。而Nginx分为内置策略和扩展策略,不同策略各自适用不同情况下使用,所以可以根据实际情况选择使用哪种策略模式,不过fair和url_hash需要安装第三方模块才能使用。
- 内置策略
- random(随机)
- round robin(轮询)
- weight(权重)
- least_conn(最少连接数)
- ip_hash(ip哈希分配)
- 扩展策略
- url_hash(url哈希分配 – Nginx 的 hash 软件包)
- fair(响应时长 – upstream_fair)
1、随机策略(random)
upstream server_group {
random;
server backend1.example.com;
server backend2.example.com;
}
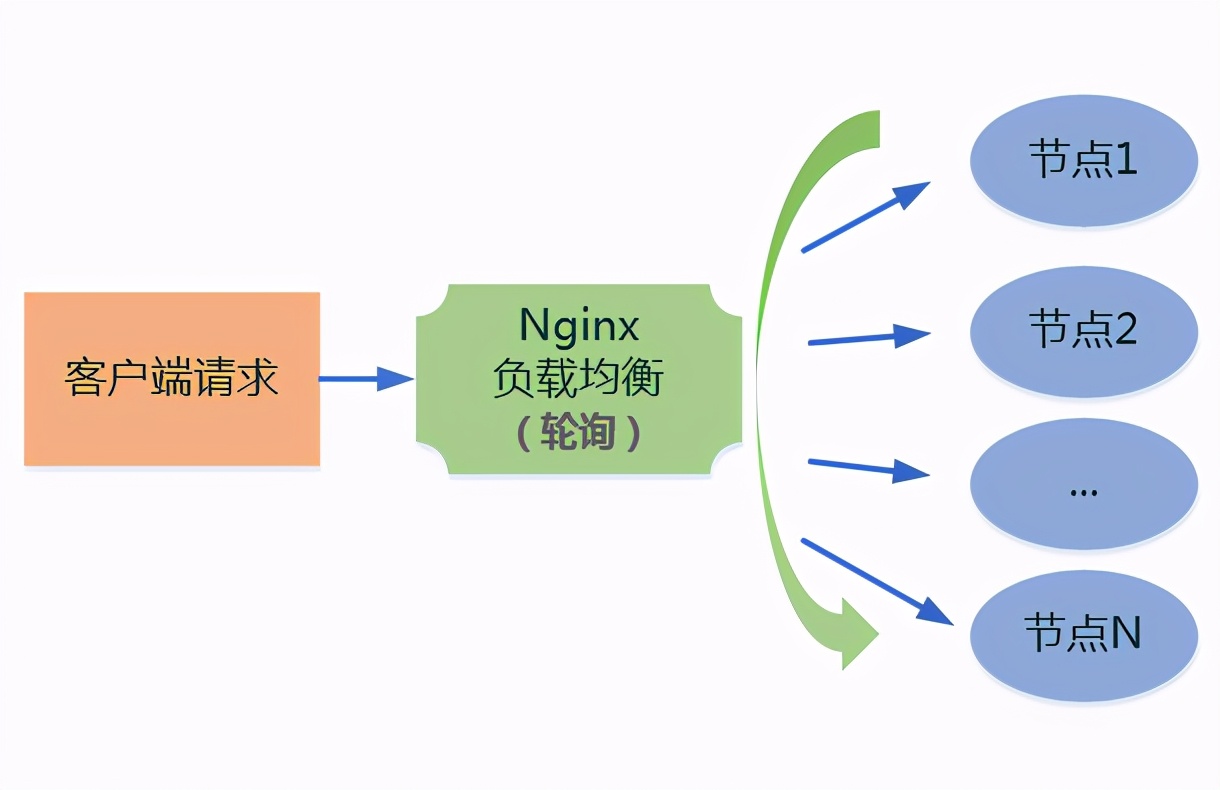
2、轮询策略(Round Robin)
nginx的默认策略为轮询策略,也就是访问的请求会依次分发给后台各个服务器,如果在后台服务器性能都相同的情况下,可以使用默认策略,当然如果其中一台服务器挂掉的话,也可以自动剔除,继续其他服务器的请求。
upstream test {
server localhost:8080;
server localhost:8081;
}
server {
listen 81;
server_name localhost;
client_max_body_size 1024M;
location / {
proxy_pass http://test;
proxy_set_header Host $host:$server_port;
}
}
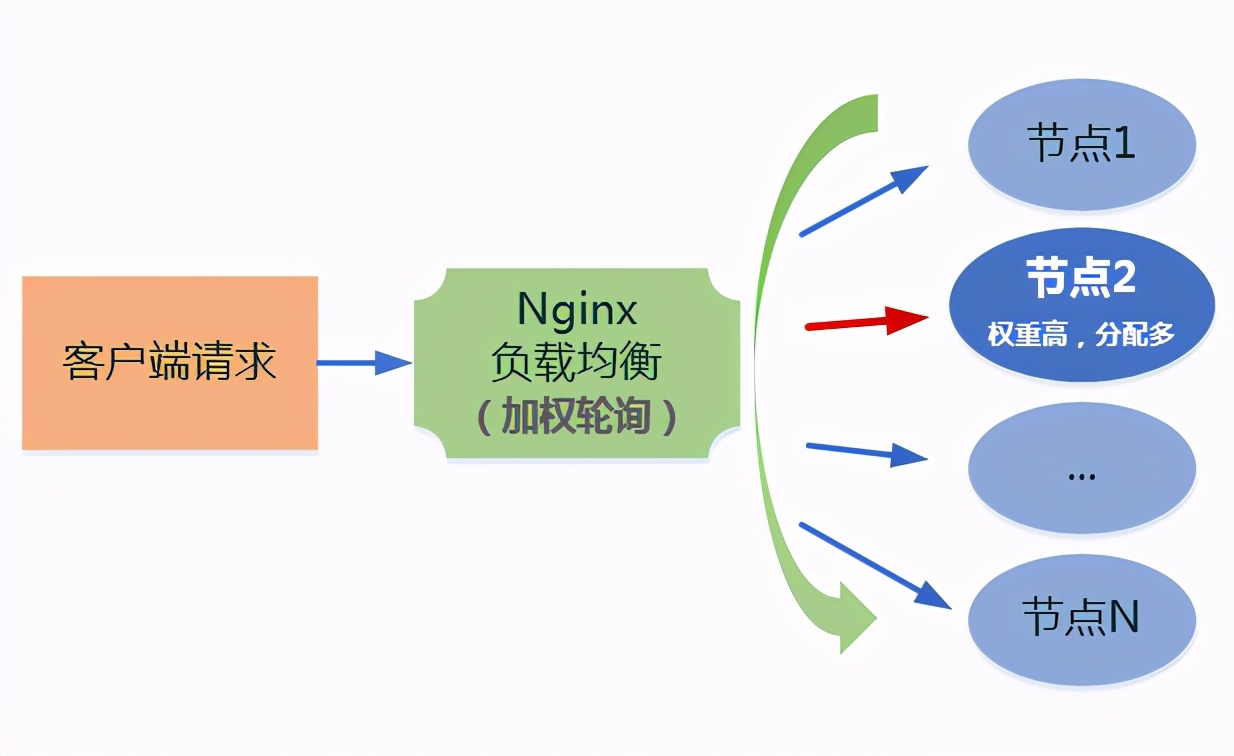
3、权重策略(weight)
权重策略就是在轮询的基础上,加上每台主机的权重,也就是主机请求的比率,可以给性能好的主机比率高点,差的地点,比如物理机可以增加比率,而虚拟机可以减少比率等。
upstream test {
server localhost:8080 weight=9;
server localhost:8081 weight=1;
}
那么10次一般只会有1次会访问到8081,而有9次会访问到8080。
4、最少连接数(least_conn)
upstream server_group {
least_conn;
server backend1.example.com;
server backend2.example.com;
}
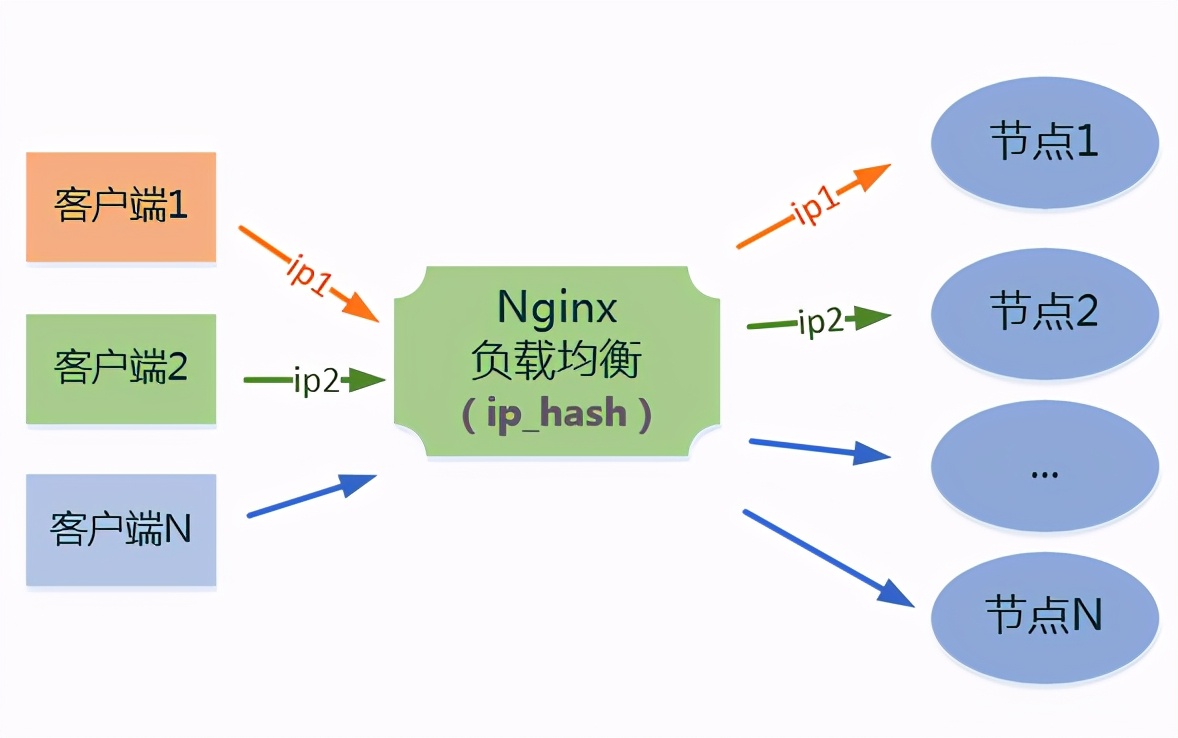
5、IP_Hash(ip哈希分配)
上面的2种方式都有一个问题,那就是下一个请求来的时候请求可能分发到另外一个服务器,当我们的程序不是无状态的时候(采用了session保存数据),这时候就有一个很大的很问题了,比如把登录信息保存到了session中,那么跳转到另外一台服务器的时候就需要重新登录了,所以很多时候我们需要一个客户只访问一个服务器,那么就需要用iphash了,iphash的每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
upstream test {
ip_hash;
server localhost:8080;
server localhost:8081;
}
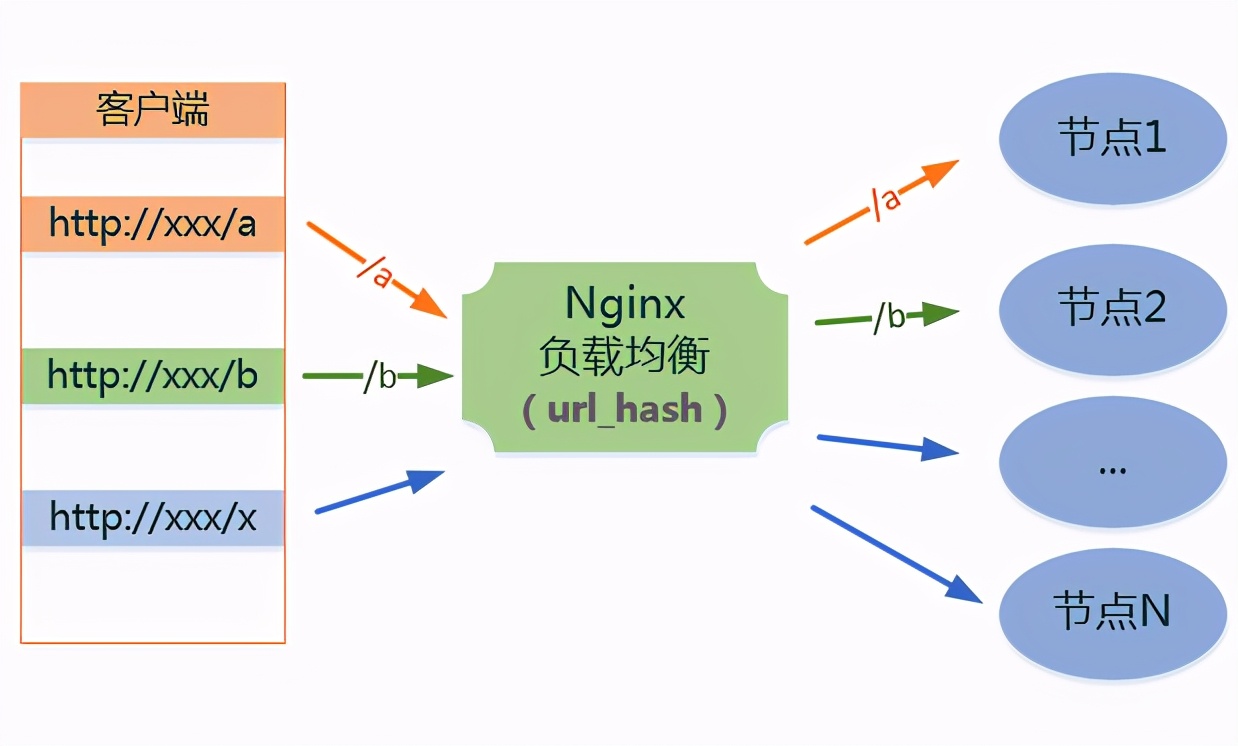
6、url_hash(url哈希分配 – 第三方)
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。 在upstream中加入hash语句,server语句中不能写入weight等其他的参数,hash_method是使用的hash算法。要使用的话需要安装Nginx的hash软件包。
upstream backend {
hash $request_uri;
hash_method crc32;
server localhost:8080;
server localhost:8081;
}
7、fair(响应时长 – 第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。如果要使用这种调度算法,请安装upstream_fair模块。
upstream backend {
fair;
server localhost:8080;
server localhost:8081;
}
失败重试
upstream backend {
server 192.168.0.1:8080 max_fails=2 fail_timeout=10s weight=1;
server 192.168.0.2:8080 max_fails=2 fail_timeout=10s weight=1;
}
- max_fails:允许请求失败的次数,默认为1。当超过最大次数时,返回proxy_next_upstream 模块定义的错误。
- fail_timeout:在经历了max_fails次失败后,暂停服务的时间。max_fails可以和fail_timeout一起使用。
健康检查(upstream_check_module)
TCP 心跳检查
upstream backend {
server 192.168.0.1:8080 weight=1;
server 192.168.0.2:8080 weight=2;
check interval=3000 rise=1 fall=3 timeout=2000 type=tcp;
}
- interval:检测间隔时间,此处配置了每隔3s检测一次。
- fall:检测失败多少次后,上游服务器被标识为不存活。
- rise:检测成功多少次后,上游服务器被标识为存活,并可以处理请求。
- timeout:检测请求超时时间配置。
HTTP心跳检查
upstream backend {
server 192.168.0.1:8080 weight=1;
server 192.168.0.2:8080 weight=2;
check interval=3000 rise=1 fall=3 timeout=2000 type=http;
check_http_send "HEAD /status HTTP/1.0\r\n\r\n";
check_http_expect_alive http_2xx http_3xx;
}
HTTP心跳配置比TCP额外多了2个配置:
- check_http_send:健康检查时所发送的请求内容。
- check_http_expect_alive:当上游服务器返回匹配的状态码,就认为上游服务器存活。
这里面需要注意的是,健康检查的时间间隔不宜过短。否则有可能会造成拥堵,更甚至造成上游服务器挂掉。
备份上游服务器
upstream backend {
server 192.168.0.1:8080 weight=1;
server 192.168.0.2:8080 weight=2 backup;
}
上面192.168.0.2被配置为备份服务器,当所有上游主机都不存活时,请求就会被转发给备份服务器。
不可用服务器
upstream backend {
server 192.168.0.1:8080 weight=1;
server 192.168.0.2:8080 weight=2 down;
}
当上游服务器出现故障时,可以通过该配置临时摘除机器。